Wat zijn SPLD's?
Een eenvoudig programmeerbaar logisch apparaat (SPLD) is een compacte elektronische component die wordt gebruikt om logische functies uit te voeren in elektronische systemen.Het staat bekend om zijn eenvoudige structuur en het vermogen om configuraties te behouden, zelfs zonder stroom.In dit artikel leer je over SPLD, de vergelijkingen met andere apparaten, de functies en hoe de modellen werken.Catalogus

Inleiding tot SPLD
Een eenvoudig programmeerbaar logisch apparaat (SPLD) is een type geïntegreerd circuit dat is ontworpen om verschillende logische bewerkingen uit te voeren.Hoewel vergelijkbaar met een complexe PLD (CPLD), wordt een SPLD meestal geleverd met minder invoer-/uitgangspennen en programmeerbare elementen.Dit maakt het krachtiger en eenvoudiger in structuur.
Om een SPLD te configureren, hebt u vaak een specifiek programmeerapparaat nodig.Fabrikanten kunnen hun unieke methoden hebben om deze apparaten te programmeren, zodat het proces kan variëren.Desondanks is een gemeenschappelijk kenmerk van SPLD's dat ze niet-vluchtig zijn.Dit betekent dat ze hun configuratie intact kunnen houden, zelfs wanneer de stroom is uitgeschakeld.
In een SPLD vindt u een verzameling programmeerbare logische poorten en punten, waardoor deze verschillende taken kan uitvoeren.Veel SPLD's omvatten ook geheugenelementen en flip-flops, wat bijdraagt aan hun veelzijdigheid bij het maken van zowel logica als op geheugen gebaseerde ontwerpen.
Vergelijking van SPLD met andere PLD's
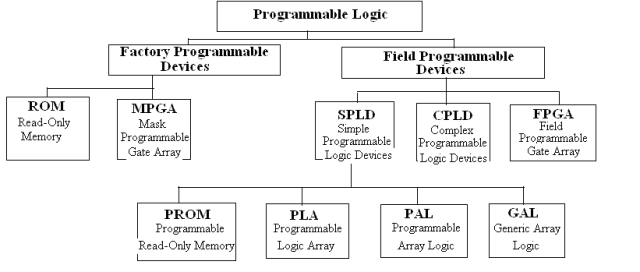
Programmeerbare logische apparaten (PLD's) zijn een brede categorie die verschillende soorten apparaten bevat, zoals programmeerbaar-alleen-lezen geheugen (prom), Wisbaar programmeerbaar-alleen-lezen geheugen (EPROM), programmeerbare logische array (PLA), programmeerbare array logic (PAL)en generieke array -logica (gal).Elk type is ontworpen met unieke structurele kenmerken en functies, zoals samengevat in de onderstaande tabel.
De structuur van een PLA deelt overeenkomsten met een prom.Beide hebben een opstelling van en poorten, of poorten en uitvoerbuffers.De en gate -array in een PLA is echter programmeerbaar en biedt meer flexibiliteit.Bij het bouwen van dezelfde logische functies, gebruikt PLAS meestal minder cellen in de en en of gate -arrays in vergelijking met proms, waardoor ze efficiënter zijn voor bepaalde toepassingen.
PAL -apparaten daarentegen bevatten soms een geregistreerde uitvoerstructuur.Hierdoor kunnen ze zowel combinatie- als opeenvolgende logische taken behandelen, waardoor ze geschikt zijn voor een breder scala aan ontwerpen.GAL-apparaten gaan nog een stap verder met hun programmeerbare macro-logische eenheden, die verschillende operationele modi bieden.Deze modi kunnen de verschillende uitvoerstructuren repliceren die worden gevonden in PAL -apparaten.
Hoewel het programmeren van PAL- en GAL-apparaten complex kan zijn vanwege de behoefte aan speciale tools en programmeertalen, zijn deze tools ontworpen om gebruiksvriendelijk te zijn.Dit maakt het werken met PAL- en GAL -apparaten toegankelijk, zelfs met hun geavanceerde mogelijkheden.
Overzicht van Atmel SPLD
Atmel SPLD -producten, zoals de 16V8 en 22V10, zijn ontworpen om te voldoen aan de industriële normen en bieden een reeks opties voor verschillende vermogens- en spanningsvereisten.Deze omvatten laagspannings-, nul-power- en kwart-powerversies, catering voor verschillende behoeften.Atmel biedt ook de "L" -serie-apparaten, die automatische power-down functionaliteit hebben, waardoor ze zeer energiezuinig zijn.Een populair voorbeeld is de ATF22LV10CQZ, een batterijvriendelijke optie.
Atmel SPLD's zijn beschikbaar in een gepatenteerd TSSOP -pakket, een van de kleinste ontwerpen voor SPLD -apparaten.Ze ondersteunen ook andere veelgebruikte verpakkingsformaten, waardoor compatibiliteit met verschillende systemen zorgt.Alle Atmel SPLD -producten zijn gebouwd met behulp van EE -technologie, waardoor betrouwbare prestaties en herhaalbare programmering worden gewaarborgd.Bovendien worden ze ondersteund door algemeen beschikbare programmeerhulpmiddelen van derden, waardoor ze gemakkelijk kunnen werken.
SPLD -modellen begrijpen
SPLD -modellen zijn ontworpen om zich te concentreren op diversiteit binnen monsters door ervoor te zorgen dat geselecteerde monsters zo gevarieerd mogelijk zijn.Deze diversiteit is gebaseerd op het idee dat monsters binnen dezelfde groep of cluster meestal meer op elkaar lijken dan die uit verschillende groepen.Deze clusteringbenadering helpt bij het vastleggen van een breed scala aan gedrag en patronen in de gegevens.
In een videoherkenningstaak worden frames van dezelfde video bijvoorbeeld beschouwd als onderdeel van hetzelfde cluster vanwege hun overeenkomsten.Aan de andere kant vertonen frames van verschillende video's diversiteit omdat ze tot verschillende clusters behoren.Dit concept is van toepassing op SPLD, waarbij de gegevensset is verdeeld in clusters en het systeem waarden toewijst aan monsters op basis van hun diversiteit binnen deze groepen.
Het model introduceert een parametermatrix die de leergewichten over meerdere clusters verdeelt.Dit zorgt ervoor dat geselecteerde monsters een breed spectrum van gegevens bestrijken in plaats van geconcentreerd te worden in één cluster.Hiermee kunnen SPLD's in evenwicht zijn tussen eenvoud (gewichten toewijzen aan eenvoudige monsters) en variëteit (kiezen uit meerdere groepen).
Een uniek kenmerk van SPLD is het gebruik van een objectieve functie die diversiteit bevordert via een methode die negatieve L2,1 -norm wordt genoemd.In tegenstelling tot traditionele SPL's die zich op een paar clusters kunnen concentreren, moedigt SPLD de verspreiding van monsterselectie over zoveel mogelijk clusters aan.Dit creëert een rijkere leerervaring door redundantie te voorkomen.
SPLD-optimalisatie volgt een stapsgewijze aanpak, afwisselend tussen het bijwerken van twee sets parameters.Door monsters te rangschikken op basis van hun verlieswaarden en een geleidelijk afnemende drempel toe te passen, zorgt SPLD ervoor dat het een mix van monsters omvat, variërend van eenvoudiger tot complexer.Dit proces zorgt voor een diverse en evenwichtige selectie, die SPLD onderscheidt van traditionele SPL -methoden.
Optimalisatieproces in SPLD
Het optimalisatieproces in SPLD richt zich op het verfijnen van hoe monsters worden gekozen en verdeeld over clusters.Het is bedoeld om diversiteit en de effectiviteit van het leren in evenwicht te brengen door een niet-convex optimalisatieprobleem op te lossen.Dit wordt bereikt door een objectieve functie:
Hier:
De functie is ontworpen om verlies te minimaliseren en tegelijkertijd een diverse steekproefselectie aan te moedigen met behulp van twee parameters, En .Deze regelen de balans tussen het focussen op eenvoudiger monsters en het waarborgen van diversiteit.
Omdat gegevens vaak in clusters worden gegroepeerd, wordt het optimalisatieprobleem opgebroken in kleinere sub-problemen.Elk cluster heeft zijn eigen optimalisatietaak:
Hier, vertegenwoordigt het verlies voor de -th monster in cluster .De oplossing zorgt ervoor dat elk cluster een diverse set monsters bijdraagt aan het algehele leerproces.
Om het selectieproces verder te verfijnen, worden monsters gerangschikt op basis van hun verlies.Een drempel, bepaald door de parameters En , past zich dynamisch aan naarmate er meer monsters zijn geselecteerd:
Als het verlies van een monster voldoet , het is geselecteerd ();Anders is het niet ().
De optimalisatie wisselt tussen bijwerken En , ervoor zorgen dat elke stap de parameters verfijnt om betere resultaten te bereiken.Door een afnemende drempel op te nemen, omvat SPLD monsters met een hoger verlies in de loop van de tijd, waardoor een mix van eenvoudiger en meer uitdagende voorbeelden wordt gewaarborgd.Deze methode verbetert de leerefficiëntie met behoud van de steekproefdiversiteit.
Deze gestructureerde benadering, in combinatie met precieze wiskundige definities, maakt SPLD effectief voor complexe, heterogene gegevensscenario's.
Over ons
ALLELCO LIMITED
Lees verder
Quick Inviry
Stuur een aanvraag, we zullen onmiddellijk reageren.

Wat is SRAM?
Op 2025/01/14

ADM699AR ANALOG Devices Alternatives, Functies, Applications
Op 2025/01/14
Populaire berichten
-

Complexe instructieset computers: hoe ze de computer hebben gewijzigd?
Op 8000/04/18 147757
-

USB-C-pinout en functies
Op 2000/04/18 111936
-
Met behulp van Xilinx Unified Simulation Primitives: een uitgebreide gids voor FPGA -ontwerp en simulatie
Op 1600/04/18 111349
-

Voedingsspanningen in elektronica: betekenis van VCC, VDD, VEE, VSS en GND
Op 0400/04/18 83721
-

RJ45 -connectorhandleiding: pinout, bedrading, kabeltypen en gebruik
Op 1970/01/1 79508
-

De ultieme gids voor draadkleurcodes in moderne elektrische systemen
De manier waarop onze elektrische systemen kleuren gebruiken, is niet alleen voor uiterlijk.Elke draadkleur geeft nu een specifieke functie aan, waardoor het gemakkelijker wordt om elektrische comp...Op 1970/01/1 66909
-

PURGE VLEP GIDS: Functie, symptomen, testen en vervanging voor optimale motorprestaties
De Purge -klep is een belangrijk onderdeel van het systeem van een auto dat helpt de lucht schoon te houden door brandstofdampen te beheren voordat ze in de atmosfeer kunnen ontsnappen.Dit helpt ni...Op 1970/01/1 63045
-

Kwaliteit (Q) Factor: vergelijkingen en toepassingen
De kwaliteitsfactor, of 'Q', is belangrijk bij het controleren hoe goed inductoren en resonatoren werken in elektronische systemen die radiofrequenties gebruiken (RF).'Q' meet hoe goed een circuit ...Op 1970/01/1 63012
-

Piekprestaties bereiken met de maximale stelling van de stroomoverdracht
De maximale stelling van de stroomoverdracht legt uit hoe energie van een bron, zoals een batterij of generator, naar een aangesloten belasting stroomt.Het toont de exacte voorwaarde waar de belast...Op 1970/01/1 54081
-

A23 Batterijspecificaties en compatibiliteit
De A23-batterij is een kleine, cilindervormige batterij met hoge spanning.Ook wel 23A, 23ae of MN21 genoemd, het loopt op 12 volt en veel hoger dan AA- of AAA -batterijen.Het speciale ontw...Op 1970/01/1 52125
Heet onderdeelnummer
-

LT8619IMSE#PBF
Analog Devices Inc.
IC REG BUCK 0.8V 1.2A 16MSOP
SN54LS173AJ
Texas Instruments
54LS173A 4-BIT D-TYPE REGISTERS
74AC109SC
Fairchild Semiconductor
IC FF JK TYPE DUAL 1BIT 16SOIC
V375C12E150BG
Vicor Corporation
DC DC CONVERTER 12V 150W
ADM8830ACP
Analog Devices Inc.
IC CHARGE PUMP REG TFT 20LFCSP
Z8F021APJ020SG
Zilog
IC MCU 8BIT 2KB FLASH 28DIP
SPC58EC80E1Q0C0X
STMicroelectronics
IC MCU 32BIT 4MB FLASH 64ETQFP
VE-2N2-CW
Vicor Corporation
DC DC CONVERTER 15V 100W
NZT902
onsemi
TRANS NPN 90V 3A SOT223-4
EDZVFHT2R16B
Rohm Semiconductor
DIODE ZENER 16V 150MW EMD2
ATMEGA329PV-10ANR
Atmel
IC MCU 8BIT 32KB FLASH 64TQFP
MM74HCT08MTCX
Fairchild Semiconductor
AND GATE, HCT SERIES, 4-FUNC, 2-
UC3853D
Texas Instruments
IC PFC CTR AVER CURR 94KHZ 8SOIC
MT46V8M16TG-75:D
Micron Technology Inc.
IC DRAM 128MBIT PARALLEL 66TSOP
DRV5015A1QDBZT
Texas Instruments
MAGNETIC SWITCH LATCH SOT23-3
TPS7A2430DBVR
Texas Instruments
IC REG LINEAR 3V 200MA SOT23-5
10118242-001RLF
Amphenol ICC (FCI)
CONN RCP MICRO HDMI 19POS SMD RA
NUF6402MNT1G
onsemi
FILTER RC(PI) 100 OHM/17PF SMD -

MAX923CPA+
Analog Devices Inc./Maxim Integrated
IC COMPARATOR 2 W/VOLT REF 8DIP
SL28506BZC-2
Skyworks Solutions Inc.
IC CLOCK CK505 PCIE GEN2 56TSSOP
LT1678CS8#TRPBF
Analog Devices Inc.
IC OPAMP GP 2 CIRCUIT 8SO
RHRG5060
NXP USA Inc.
RECTIFIER DIODE, AVALANCHE, 1 PH
TLC3704CN
Texas Instruments
IC COMPARATOR 4 GEN PUR 14DIP
W1524LC300
IXYS
DIODE GEN PURP 3KV 1524A W4
TPS2041BDBVR
Texas Instruments
IC PWR SWITCH N-CHAN 1:1 SOT23-5
VI-250-EY
Vicor Corporation
DC DC CONVERTER 5V 50W
RMPA0959
Fairchild Semiconductor
IC RF AMP CELL 824-849MHZ 11LCC
SMCJ16CA-E3/57T
Vishay General Semiconductor - Diodes Division
TVS DIODE 16VWM 26VC DO214AB
SN74CBT3125PWR
Texas Instruments
IC BUS SWITCH 1 X 1:1 14TSSOP
ACT412US-T
Active-Semi
IC OFF-LINE SWITCH PWM 6SOT-23
VNB14NV0413TR
STMicroelectronics
IC PWR DRIVER N-CHAN 1:1 D2PAK
C1608X7R2A102M/10
TDK Corporation
CAP CER 1000PF 100V X7R 0603
C2012JB1A685K085AC
TDK Corporation
CAP CER 6.8UF 10V JB 0805
EPM3128ATC100-5
Intel
IC CPLD 128MC 5NS 100TQFP
LTC2950ITS8-2#TRMPBF
Analog Devices Inc.
IC PB ON/OFF CONTROLLER TSOT23-8
BLM21BB221SN1D
Murata Electronics
FERRITE BEAD 220 OHM 0805 1LN -

THS6226AIRHBT
Texas Instruments
IC TELECOM INTERFACE 32VQFN
LV8481CS-TE-L-H
onsemi
IC MTR DRVR BIPLR 2.4-4.5V 10WLP
SSF2300
Good-Ark Semiconductor
MOSFET, N-CH, SINGLE, 4.5A, 20V,
CYPD2134-24LQXI
Infineon Technologies
IC MCU 32BIT 32KB FLASH 24QFN
SBR20A100CT
Diodes Incorporated
DIODE ARRAY SBR 100V 10A TO220AB
93LC46B-I/MS
Microchip Technology
IC EEPROM 1KBIT MICROWIRE 8MSOP
74HCT1G14GV,125
Nexperia USA Inc.
IC INVERT SCHMITT 1CH 1-IN SC74A
L78M09CDT-TR
STMicroelectronics
IC REG LINEAR 9V 500MA DPAK
HRPG-ASCA#13R
Broadcom Limited
ROTARY ENCODER OPTICAL 120PPR
IRFR9220TRPBF
Vishay Siliconix
MOSFET P-CH 200V 3.6A DPAK
ISL81487LIB
Intersil
IC TRANSCEIVER HALF 1/1 8SOIC
UPD78F0511AGB-GAF-AX
Renesas Electronics America Inc
IC MCU 8BIT 16KB FLASH 44LQFP
PCM1737E/2K
Texas Instruments
IC DAC/AUDIO 24BIT 200K 28SSOP
V24B15H200BG3
Vicor Corporation
DC DC CONVERTER 15V 200W
AB-13.560MANH-T
TXC CORPORATION
CRYSTAL 13.5600MHZ 15PF SMD
XC6220B281PR-G
Torex Semiconductor Ltd
IC REG LINEAR 2.8V 1A SOT89-5
KSZ9131RNXC
Microchip Technology
IC TXRX FULL/HALF 4/4 48QFN
12062C223MAT2A
KYOCERA AVX
CAP CER 0.022UF 200V X7R 1206