Principes en toepassingen van de klassieke testtheorie (CTT)
Deze gids biedt een diepgaande verkenning van de principes en praktische toepassingen van de klassieke testtheorie (CTT), een raamwerk in psychologische en educatieve metingen.Door een gestructureerde reis duikt het in de oorsprong, concepten zoals echte scores, wiskundige kaders en hypothesen.Deze gids bestrijkt u de kennis om CTT -principes effectief te begrijpen en toe te passen, waardoor een mix van historische context, technische details en praktische strategieën wordt geboden om de betrouwbaarheid en geldigheid van de beoordeling te verbeteren.Catalogus

Oorsprong
De klassieke testtheorie (CTT) ontstond in de late 19e eeuw en werd door de jaren 1930 gerijpt, waardoor de basis werd gelegd voor moderne psychologische en educatieve metingen.Belangrijkste bijdragen, zoals het werk van Glickson in de jaren 1950, versterkten zijn wiskundige grondslagen en benadrukten het belang van betrouwbaarheid en geldigheid bij beoordelingen.Een moment kwam in 1968 met Lord en Nowick's mijlpaalpublicatie, statistische theorie van psychologische testscores, die het begrip van testscores en factoren die hen beïnvloeden, zoals test-taker-kenmerken en milieucontexten geavanceerd.De principes van CTT worden op grote schaal toegepast in gestandaardiseerde testen, waarbij uitdagingen zoals bias en itemverfijning worden aangepakt terwijl het streven naar nauwkeurige en eerlijke metingen.In de loop van de tijd is de theorie geëvolueerd door een dynamisch samenspel van praktijk en onderzoek, het vormgeven van huidige methoden en het blijven voor educatieve en psychologische beoordelingen.
Juiste fractie
In psychologisch onderzoek is het concept van echte scores nodig om gedrag en cognitie nauwkeurig te meten, vrij van de invloed van meetfouten.Echte scores worden bepaald door het gemiddelde te nemen van meerdere beoordelingen om willekeurige fouten te minimaliseren.Deze fouten kunnen voortkomen uit factoren zoals gebrekkige hulpmiddelen, situationele context of mentale toestanden van de deelnemers tijdens het testen, waardoor het wordt gebruikt om beoordelingsmethoden te verfijnen.Goed ontworpen vragenlijsten en betrouwbare tools kunnen bijvoorbeeld fouten verminderen, het vertrouwen in bevindingen verbeteren en de onderzoekskwaliteit verbeteren.Echte scores hebben ook praktische implicaties, zoals het in staat stellen van opvoeders om eerlijkere beoordelingsstrategieën te creëren door te vertrouwen op meerdere evaluaties in plaats van enkele testscores.Echte scores zijn verweven met betrouwbaarheid (meetconsistentie) en validiteit (nauwkeurigheid van wat wordt gemeten), en benadrukken het belang van het verfijnen van hulpmiddelen om ervoor te zorgen dat beoordelingen zowel consistent als zinvol blijven.
Wiskundige kader
Het wiskundige raamwerk, voorgesteld door de vergelijking x = T + E, verklaart de relatie tussen de waargenomen score (x), de echte score (t) en meetfout (e).In deze context dragen willekeurige fouten bij aan E, terwijl systematische fouten worden verantwoord binnen T. De waargenomen score weerspiegelt de uitkomst van een meting, terwijl de echte score de ideale, foutloze waarde vertegenwoordigt.Willekeurige fouten zijn onvoorspelbaar en kunnen voortkomen uit factoren zoals omgevingscondities of variabiliteit van de test-taker, vaak beperkt door herhaald testen.Systematische fouten daarentegen zijn consistent en vereisen zorgvuldig onderzoek van meetinstrumenten en methoden.Dit raamwerk benadrukt het belang van het minimaliseren van fouten om de nauwkeurigheid, betrouwbaarheid en geldigheid bij beoordelingen te waarborgen.Praktische strategieën, zoals het standaardiseren van testomgevingen en trainingsevaluaties, verbeteren de betrouwbaarheid van de meet.Inzicht in de implicaties van X = T + E is belangrijk voor het verantwoorde interpretatie van gegevens, het vermijden van verkeerd inschattingen en ervoor zorgen dat beslissingen zijn gebaseerd op gezond bewijs.Dit raamwerk toont het nastreven van precisie in meting om de kwaliteit van inzichten en resultaten te verbeteren.
Hypothesen
Uit de vastgestelde vergelijking kunnen we drie onderling verbonden hypothesen afleiden die de complexiteit van meet en fouten in psychologische beoordelingen onderzoeken.
Ten eerste, wanneer N -metingen worden genomen, heeft de gemiddelde fout de neiging nul te benaderen.Deze observatie leidt ertoe dat we concluderen dat de echte score aansluit op de gemiddelde waargenomen score, wiskundig uitgedrukt als t = e (x) of e (e) = 0. Deze hypothese benadrukt de betekenis van het hebben van een voldoende grote steekproefomvang om betrouwbare resultaten te bereiken.Grotere monsters hebben de neiging om de impact van willekeurige schommelingen te verminderen en biedt een duidelijkere en nauwkeuriger weergave van de echte score.
Ten tweede stellen we voor dat echte scores en meetfouten onafhankelijk werken, aangegeven door ρ (t, e) = 0. Deze onafhankelijkheid is nodig om de integriteit van psychologische beoordelingen te handhaven, omdat het suggereert dat systematische vooroordelen de echte score niet beïnvloeden.In de praktijk vereist het bereiken van deze onafhankelijkheid rigoureuze testprotocollen en het gebruik van gevalideerde instrumenten die een grondige betrouwbaarheid en validiteitsevaluaties hebben ondergaan.Dergelijke maatregelen kunnen helpen de invloed van potentiële verwarrende variabelen te verlichten die de resultaten kunnen vervormen.
Ten derde beweren we dat fouten die voortvloeien uit parallelle tests nul zijn, weergegeven als ρ (E1, E2) = 0. De bruikbaarheid van het herhaaldelijk beoordelen van dezelfde psychologische eigenschappen door parallelle tests staat echter vaak voor uitdagingen.Verschillende factoren, waaronder de noodzaak van consistentie in eigenschappen, proefpersonen, testmoeilijkheden en differentiatie, bemoeilijkt dit streven.Over het algemeen wordt een enkele test toegediend aan een groep, waarbij individuele fouten worden verondersteld willekeurig en normaal verdeeld te zijn.Deze veronderstelling is belangrijk, omdat het de toepassing van statistische methoden voor effectieve gegevensanalyse en interpretatie vergemakkelijkt.
De relatie tussen de varianties van waargenomen scores, echte scores en foutscores binnen een groep kan worden gearticuleerd via de vergelijking SX = ST + SE.Deze formule is voornamelijk verantwoordelijk voor willekeurige fouten, terwijl de variantie van systematische fouten is geïntegreerd in de echte scorevariantie.Naarmate we ons begrip verdiepen, kunnen we deze vergelijking verfijnen tot Sx = Sv + Si + SE, waarbij SV variantie aangeeft gerelateerd aan de meetdoelstelling en Si de variantie ervan betekent onafhankelijk ervan.Dit perspectief erkent dat niet alle variantie kan worden toegeschreven aan meetfout, waardoor de complexiteit van psychologische constructen en het veelzijdige natuurgedrag wordt belicht.
Concluderend, deze hypothesen verlichten het ingewikkelde samenspel tussen echte scores, meetfouten en hun varianties in psychologische metingen.Het herkennen van deze dynamiek versterkt niet alleen de strengheid van onze beoordelingsmethoden, maar verbetert ook ons begrip van de psychologische constructen die we willen meten.
Over ons
ALLELCO LIMITED
Lees verder
Quick Inviry
Stuur een aanvraag, we zullen onmiddellijk reageren.

IRQ Basics: wat zijn interruptverzoeken en hoe werken ze?
Op 2024/12/31
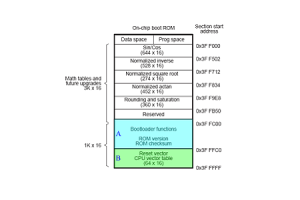
Interrupt Vector Tabel: architectuur, management en applicaties
Op 2024/12/31
Populaire berichten
-

Complexe instructieset computers: hoe ze de computer hebben gewijzigd?
Op 8000/04/19 147781
-

USB-C-pinout en functies
Op 2000/04/19 112056
-
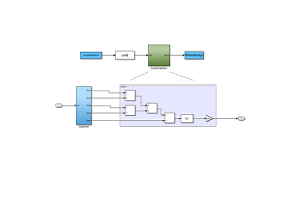
Met behulp van Xilinx Unified Simulation Primitives: een uitgebreide gids voor FPGA -ontwerp en simulatie
Op 1600/04/19 111352
-

Voedingsspanningen in elektronica: betekenis van VCC, VDD, VEE, VSS en GND
Op 0400/04/19 83810
-

RJ45 -connectorhandleiding: pinout, bedrading, kabeltypen en gebruik
Op 1970/01/1 79622
-

De ultieme gids voor draadkleurcodes in moderne elektrische systemen
De manier waarop onze elektrische systemen kleuren gebruiken, is niet alleen voor uiterlijk.Elke draadkleur geeft nu een specifieke functie aan, waardoor het gemakkelijker wordt om elektrische comp...Op 1970/01/1 66992
-

PURGE VLEP GIDS: Functie, symptomen, testen en vervanging voor optimale motorprestaties
De Purge -klep is een belangrijk onderdeel van het systeem van een auto dat helpt de lucht schoon te houden door brandstofdampen te beheren voordat ze in de atmosfeer kunnen ontsnappen.Dit helpt ni...Op 1970/01/1 63118
-

Kwaliteit (Q) Factor: vergelijkingen en toepassingen
De kwaliteitsfactor, of 'Q', is belangrijk bij het controleren hoe goed inductoren en resonatoren werken in elektronische systemen die radiofrequenties gebruiken (RF).'Q' meet hoe goed een circuit ...Op 1970/01/1 63057
-

Piekprestaties bereiken met de maximale stelling van de stroomoverdracht
De maximale stelling van de stroomoverdracht legt uit hoe energie van een bron, zoals een batterij of generator, naar een aangesloten belasting stroomt.Het toont de exacte voorwaarde waar de belast...Op 1970/01/1 54097
-

A23 Batterijspecificaties en compatibiliteit
De A23-batterij is een kleine, cilindervormige batterij met hoge spanning.Ook wel 23A, 23ae of MN21 genoemd, het loopt op 12 volt en veel hoger dan AA- of AAA -batterijen.Het speciale ontw...Op 1970/01/1 52206
Heet onderdeelnummer
-

MP4460DQ-LF-Z
Monolithic Power Systems Inc.
IC REG BUCK ADJ 2.5A 10QFN
NCV8535MNADJR2G
onsemi
IC REG LIN POS ADJ 500MA 10DFN
LT8362EDD#PBF
Analog Devices Inc.
IC REG BST SEPIC 2A 10DFN
LTC3112IFE#TRPBF
Analog Devices Inc.
IC REG BCK BST ADJ 2.5A 20TSSOP
TPS53681RSBT
Texas Instruments
DUAL-CHANNEL 6+2/5+3 D-CAP+TM MU
CD74HCT11M
Harris Corporation
IC GATE AND 3CH 3-INP 14SOIC
UCC25702N
Texas Instruments
IC REG CTRLR MULT TOPOLOGY 14DIP
MAX5418META+T
Analog Devices Inc./Maxim Integrated
IC DGTL POT 100KOHM 256TAP 8TDFN
CY29942AI
Infineon Technologies
IC CLK BUFFER 1:18 200MHZ 32TQFP
MBR20200CTTU
Fairchild Semiconductor
RECTIFIER DIODE, SCHOTTKY, 1 PHA
AD8669ARZ
Analog Devices Inc.
IC OPAMP GP 4 CIRCUIT 14SOIC
BZX55C11
onsemi
DIODE ZENER 11V 500MW DO35
FODM2701BR2V
onsemi
OPTOISO 3.75KV TRANSISTOR 4SMD
1N4746A
Taiwan Semiconductor Corporation
DIODE ZENER 18V 1W DO204AL
LB11948T-TLM-E
onsemi
IC MTR DRV BIPOLAR 3-15V 30TSSOP
LTC1412CG#PBF
Analog Devices Inc.
IC ADC 12BIT SAR 28SSOP
SP1491EEN-L
MaxLinear, Inc.
IC TRANSCEIVER FULL 1/1 14SOIC
SML-E12DWT86
Rohm Semiconductor
LED ORANGE DIFFUSED 0603 SMD -

AP1661P-G1
Diodes Incorporated
IC PFC CTRLR BCM 8DIP
NTK3139PT1G
onsemi
MOSFET P-CH 20V 660MA SOT723
2SC2412KT146Q
Rohm Semiconductor
TRANS NPN 50V 0.15A SMT3
W632GU8NB-11
Winbond Electronics
IC DRAM 2GBIT PAR 78VFBGA
08055A0R5CAT2A
KYOCERA AVX
CAP CER 0.5PF 50V C0G/NP0 0805
SUD50P10-43L-E3
Vishay Siliconix
MOSFET P-CH 100V 37.1A TO252
BAT68E6327
Infineon Technologies
BAT68 - RF MIXER AND DETECTOR SC
MIC280-0BM6TR
Microchip Technology
IC SUPERVISOR SOT23-6
LP5912Q1.8DRVRQ1
Texas Instruments
IC REG LINEAR 1.8V 500MA 6WSON
LM4866MTEX
Texas Instruments
AUDIO AMPLIFIER, 3.2W, 2 CHANNEL
MC78LC30HT1G
onsemi
IC REG LINEAR 3V 50MA SOT89-3
DS2731E+
Analog Devices Inc./Maxim Integrated
IC BAT PWR MGT LI-ION 1C 28TSSOP
ONET8501PBRGTR
Texas Instruments
IC LIMITING 1 CIRCUIT 16VQFN
W25Q80JVSSIQ
Winbond Electronics
IC FLASH 8MBIT SPI/QUAD 8SOIC
560125-0600
Molex
NEW 2.0 W/B CONN REC. 6 WAY ISL
GR332DD72W104KW01L
Murata Electronics
CAP CER 0.1UF 450V X7T 1210
CL05C330JB5NNNC
Samsung Electro-Mechanics
CAP CER 33PF 50V C0G/NP0 0402
LMR14020SQDPRTQ1
Texas Instruments
IC REG BUCK ADJUSTABLE 2A 10WSON -

SPC5668GK0VMG
NXP USA Inc.
IC MCU 32BIT 2MB FLASH 208MAPBGA
6N138W
onsemi
OPTOISO 2.5KV DARL W/BASE 8DIP
08055A3R0CAT2A
AVX Corporation
CAP CER 3PF 50V C0G/NP0 0805
BF420-AP
Micro Commercial Co
TRANS NPN 300V 0.1A TO92
SMLJ14CA
Bourns Inc.
TVS DIODE 14VWM 23.2VC SMC
VI-JN2-EW
Vicor Corporation
DC DC CONVERTER 15V 100W
BCM5892PC0KFB266G
Broadcom Limited
SECURE PROCESSOR
TPS59603QDSGRQ1
Texas Instruments
DRIVER COMPUTING
VVZ175-12IO7
IXYS
RECT BRIDGE 3PH 167A 1200V PWSE2
TPS7B6925QDBVRQ1
Texas Instruments
IC REG LINEAR 2.5V 150MA SOT23-5
IPS80R1K4P7
Infineon Technologies
IPS80R1K4 - 800V COOLMOS N-CHANN
ASSR-402C-302E
Broadcom Limited
SSR RELAY SPST-NO 40MA 0-400V
IRG4BC10SD-LPBF
Infineon Technologies
IGBT 600V 14A 38W TO262
SM843256KA
Microchip Technology
IC CLK/FREQ SYNTH 24TSSOP
LM158APT
STMicroelectronics
IC OPAMP GP 2 CIRCUIT 8TSSOP
SB140-E3/73
Vishay General Semiconductor - Diodes Division
DIODE SCHOTTKY 40V 1A DO204AL
EP2C8F256C7N
Intel
IC FPGA 182 I/O 256FBGA
BA50BC0WT
Rohm Semiconductor
IC REG LINEAR 5V 1A TO220-5